Hadoop学习系列之:spark生态体系
Spark生态体系
1. Spark基本原理
####1.1 Spark概述
基于内存计算的、分布式批处理引擎,适合应用在迭代计算、交互式分析等场景。
- 容错性,可扩展性
大多数现有集群计算框架如MR等都是基于从稳定存储(文件系统)到稳定存储的非循环数据流,数据重用都是基于磁盘的,执行效率比较低。
特点:
- 轻,源代码:scala语言
- 快,某些时候比MR性能高100倍
- 灵活
- 巧妙的和hadoop无缝对接,可以利用hadoop的周边服务
- 开发效率更高
1.2 Spark技术架构
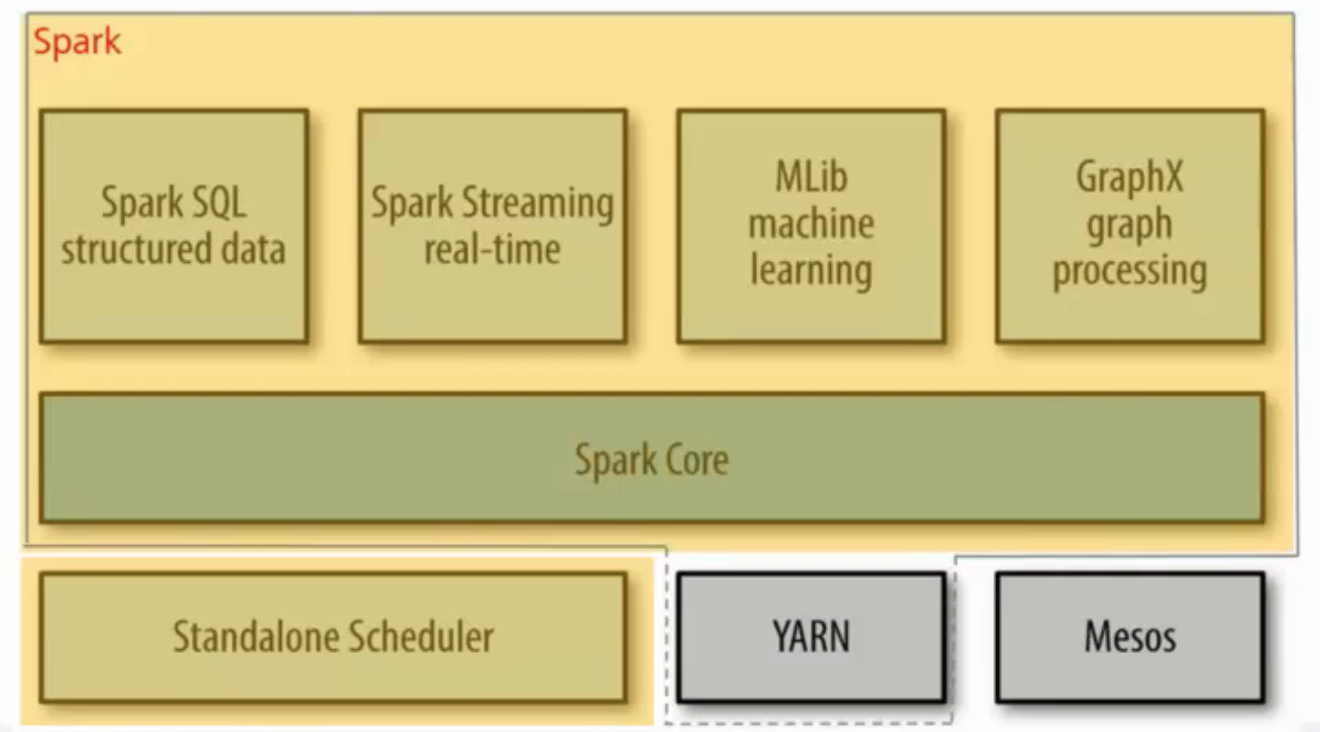
- 资源调配层:
- Standalone Scheduler:管理开源的spark
- Spark on YARN:HUAWEI使用
- Spark on Mesos
- Spark Core:spark计算核心,将中间计算结果直接放在内存,提高计算性能
- Spark应用框架:
- Spark SQL structured data:处理结构化数据的spark组件、对数据执行类sql的查询
- Spark Streaming real-time:steaming是华为对storm的一个封装(微批式),实时性比storm差点,但是吞吐量大
- MLib machine learning:分类、聚类等
- GraphX graph processing:图计算:研究客观世界中事物事物之间的关系、然后对事物进行刻画和分析。场景:社交网络分析、生物学、工程制造(集成电路设计)、安全分析等等
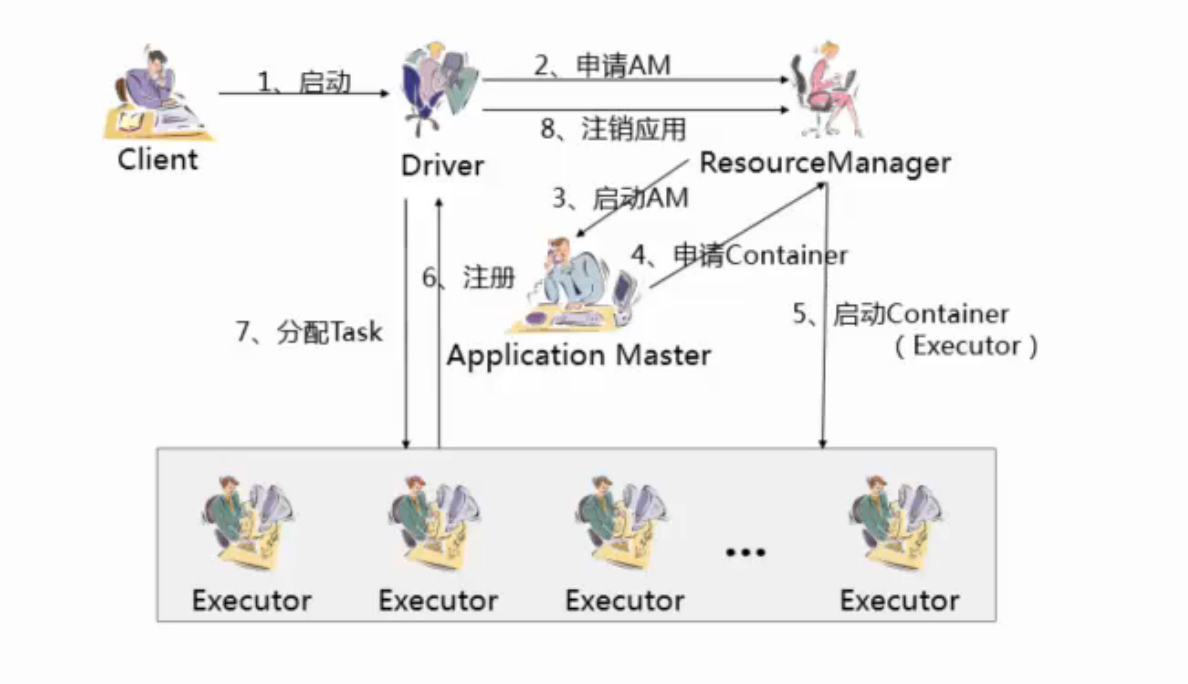
1.3 Spark应用运行流程——角色
- Client:需求提出方,负责提交需求(应用)
- Driver:spark大脑,负责应用的业务逻辑和运行规划(DAG图)
- ApplicationMaster:负责应用的资源管理,根据应用的需要向资源管理部门(RM)申请资源
- ResourceManager:资源管理部门,负责整个集群的资源统一调度和分配
- Executor:负责实际计算工资,一个应用application拆分成多个exector来进行计算。
- task:具体计算单位,每个executor有一个或多个task,每个task对应一个job
1.4 Spark应用运行流程
1.5 Spark application基本概念
- Application:Spark用户程序,提交一次应用为一个application,一个APP会启动一个SparkContext,也就是app的driver,驱动整个app的运行
- Job:一个app可能包含多个job,每个action算子对应一个job;action算子有collect、count等
- Stage:每个job可能包含剁成多个stage,划分标记为shuffle过程(连接不同stage的纽带);stage按照依赖关系依次执行。
- task:具体执行任务基本单位,被发动executor上执行
2. Spark RDD
RDD,Resilient Distributed Datasets,弹性分布数据集,指一个只读的、可分区的分布式数据集。这个数据集的全部或部分可以缓存在内存中,在多次计算中重用。
2.1 RDD生成
- 从hadoop文件系统(或与hadoop兼容的其他存储系统)输入创建(如hdfs)
- 从父RDD转换得到新的RDD
2.2 RDD优点
- RDD是只读的,可提供更高的容错能力。
- RDD是只读的,所以有不可变性,可实现hadoop MR的推测式执行(若某节点没有在规定时间内完成相应任务,则MR会启动另一个节点做同样的任务,先完成的那个结果被采用,另外一个killed。因为数据不变,所以重新计算是可行的)。
- RDD的数据分区特性,可以通过数据的本地性来提高性能(计算就近)
- RDD都是可序列化的,在内存不足时可自动化降级为磁盘存储。
2.3 RDD存储和分区
- 用户可以根据不同的存储级别存储RDD——11种方式
- RDD在需要进行分区时会根据每条记录key进行分区,保证两个数据集能高效进行join操作(可序列化)。
2.4 RDD特点
- 在集群节点上不可变的,是已分区的集合对象
- 失败后会自动重建(父RDD)
- 可以控制存储级别(内存、磁盘等)来进行重用
- 必须是可序列号的
- 是静态类型
2.5 RDD的创建
spark所有的操作都是围绕RDD进行,这是一个有容错机制并可以被并行操作的元素集合,具有只读、分区、容错、高效、无需物化、可以缓存、RDD依赖(宽依赖和窄依赖)等特征。
目前有两种基础RDD:
-
并行集合:接收一个已经存在的scala集合,然后进行并行计算
并行集合是通过调用SparkContext的parallelize方法,在一个已经存在的scala集合(一个seq对象)上创建的。集合的对象将会被copy,创建出一个可以被并行操作的分布式数据集。
-
hadoop数据集:在一个文件的每条记录上运行函数,只要文件系统是hdfs或Hadoop支持的任意存储系统
spark可以将任何hadoop支持的存储资源转换成RDD,如本地文件、hdfs、cassandra、hbase等,spark支持文本文件(slice数目不能少于block数目)、SequenceFiles(hadoop用来存储二进制key value而设计的平面文件)、任何Hadoop InputFormat格式(调用sparkContext.hadoopRDD方法)、通过transformation算子将hadoop RDD转换成其他RDD、通过血统机制转换RDD等。
这两种类型的RDD都可以通过相同的方式进行操作,从而获得子RDD一系列扩展,形成RDD血统关系图。
2.6 RDD算子
-
transformation算子
返回值还是一个RDD,如map、filter、join等。transfo是lazy的,代码调用到transformation的时候不会马上执行,需要等到action操作的时候才会启动真正计算过程。
-
action算子
如count、collect、save等,action操作是返回结果或者将结果写入存储的操作。Action是spark应用真正执行的触发动作。
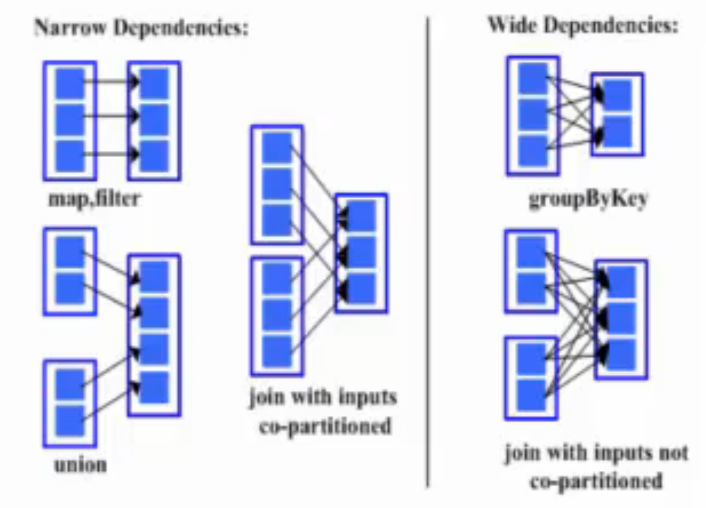
2.7 RDD依赖:宽依赖和窄依赖
-
窄依赖:父RDD的每一个分区最多被一个子RDD的分区所用——一对一
优点:窄依赖可以支持在同一个class loader上以管道形式执行多调命令,例如在执行map之后紧接着就可以执行filter;从恢复角度考虑,子RDD数据丢失,只需要从父RDD的一个分区去找,恢复有效;对优化有力,减少全局barrier,无需物化中间结果的RDD,成为pipeline优化。
-
宽依赖:子RDD的分区依赖于父RDD的所有分区,是stage的划分依据。 ——一对多
stage划分:spark从DAG图末端出发,逆向遍历整个依赖关系,遇到宽依赖就断开,遇到窄依赖就将其加在当前的stage中。stage中task个数由stage末端的rdd分区个数来决定的,rdd转换是基于分区的粗粒度的计算,一个stage执行的结果就是这几个分区构成的RDD。
 、
、
2.8 RDD样例程序-wordcount
!
3. Spark on Yarn
-
资源调度框架Yarn分为yarn-cluster和yarn-client两种模式,区别在于AppMaster不同。
yarn-cluster中AppMaster不仅负责资源分配、还负责监控task运行情况,此时client可以关掉了。——适合做生产,可以更快的看到app的输出
yarn-client中AppMaster只负责申请和分配资源,监控任务由client中的driver执行,此时client不可关掉。——适合做测试
4. Spark Streaming
Spark Streaming是spark核心API的一个扩展,对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。可以从kafka、hdfs等源获取数据,也可以通过高阶函数map、reduce、join、window等组成复杂算法计算出数据。最后处理好的数据可以推送到文件系统、数据库、实时仪表盘中。
4.1 spark streaming原理
- Spark streaming接受实时的输入数据流,然后将这些数据切分成批数据供spark引擎处理(因为会切分的非常小,当足够小的时候可以近似看出流式数据,因此又称为微批式数据),spark引擎(core)将数据生成最终的结果数据。
- 使用DStream从kafka和hdfs等获得连续的数据流,streams由一系列RDD组成,每个RDD包含确定时间间隔的数据,任何对DStreams的操作都转成成对RDD的操作。
4.2 特点
- 高吞吐量、容错能力强
- 数据采集逐条进行,数据处理分批进行。批处理的时间间隔是核心参数,可以达到毫秒级别,最小可以到50ms,一般建议设置>=500ms
- spark streaming牺牲一些实时性,提高吞吐量
优点:
- 粗粒度处理方式可以快速处理小批量数据
- 可以确保“处理且仅处理一次”,方便实现容错恢复机制
- DStream操作基于RDD操作,降低学习成本
缺点:
- 粗粒度处理引入不可避免的延迟,所以说比storm实时性要差一些
4.3 spark streaming数据源和可靠性
Spark Streaming数据源:
- 基本源:HDFS等文件系统、socket连接等
- 高级源:kafka等
- 自定义源:需要实现用户自定义receiver
可靠性(二次开发):
- reliable receiver:能正确应答一个可靠源,确保数据被接受并且被正确复制到spark中
- 设置checkPoint
- 确保driver可以自动重启
- 使用wirte ahead log功能(WAL文件)
####4.4 Spark Streaming代码流程
常见业务代码逻辑:
- 创建StreamingContext
- 定义输入源
- 准备应用计算逻辑
- 使用streamingContext.start()方法接收和处理数据
- 使用streamingContext.stop()方法停止流计算
注意:
- 在JVM中,同一时间只能有一个StreamingContext处于活跃状态
- 可以在一个应用中创建多个DStream来接收多个数据流,每个输入流DStream与一个receiver对象关联,receiver从源中获取数据,并将数据存入内存中用于处理
- receiver作为常驻进程运行在executor中,将占用一个核。因此给每个app分配的core的个数要大于receiver的个数。
4.5 Spark Streaming窗口操作
窗口定义:
窗口按照驱动类型分为:time window和account window。可以是时间或者数据驱动的。
按照固定时间划分的窗口叫时间滚动窗口,按照固定事件发生数量划分的窗口叫做事件滚动窗口。
将事件汇聚到窗口中,由非活跃时间隔开,叫做会话窗口,由事件之前时间间隔区分。
平滑窗口聚合:如按照每30s对之前一分钟的事件计算一次,叫做时间滑动窗口;如按照事件数量每10个事件计算一次,叫做事件滑动窗口。
Spark Streaming支持窗口计算(window-based operation),允许用户在一个滑动窗口数据应用transformation算子。窗子在源DStream上滑动,合并和操作落入窗内的源RDDs,产生窗口化的DStream的RDDs。
需要指定窗口长度、窗口滑动间隔,这两个参数最好设置为批处理时间间隔的倍数。
窗口操作的常用算子
4.6 Spark Streaming性能调优
- 设置合理的批处理时间(batchDuration)
- 设置合理的数据接收并行度
- 设置多个receiver接收数据
- 设置合理的receiver阻塞时间
- 设置合理的数据处理并行度:数据在存入spark内存之前都被合并成大的数据块,每批数据的个数决定了任务的个数,阻塞时间由spark.streaming.blockinterval决定,默认200ms;使用spark.default.areas设置并发任务数
- 使用Kryo系列化
- 内存调优
- 设置持久化级别减少GC开销
- 使用并发的标记-清理GC算法减少GC暂停时间
5. Spark SQL
用于结构化数据处理和类sql查询,通过spark sql可以针对不同数据类型和数据源执行ETL操作。
类似spark core的执行,只是多了一个sql语句解析成算子的过程。
SparkSQL使用方式:
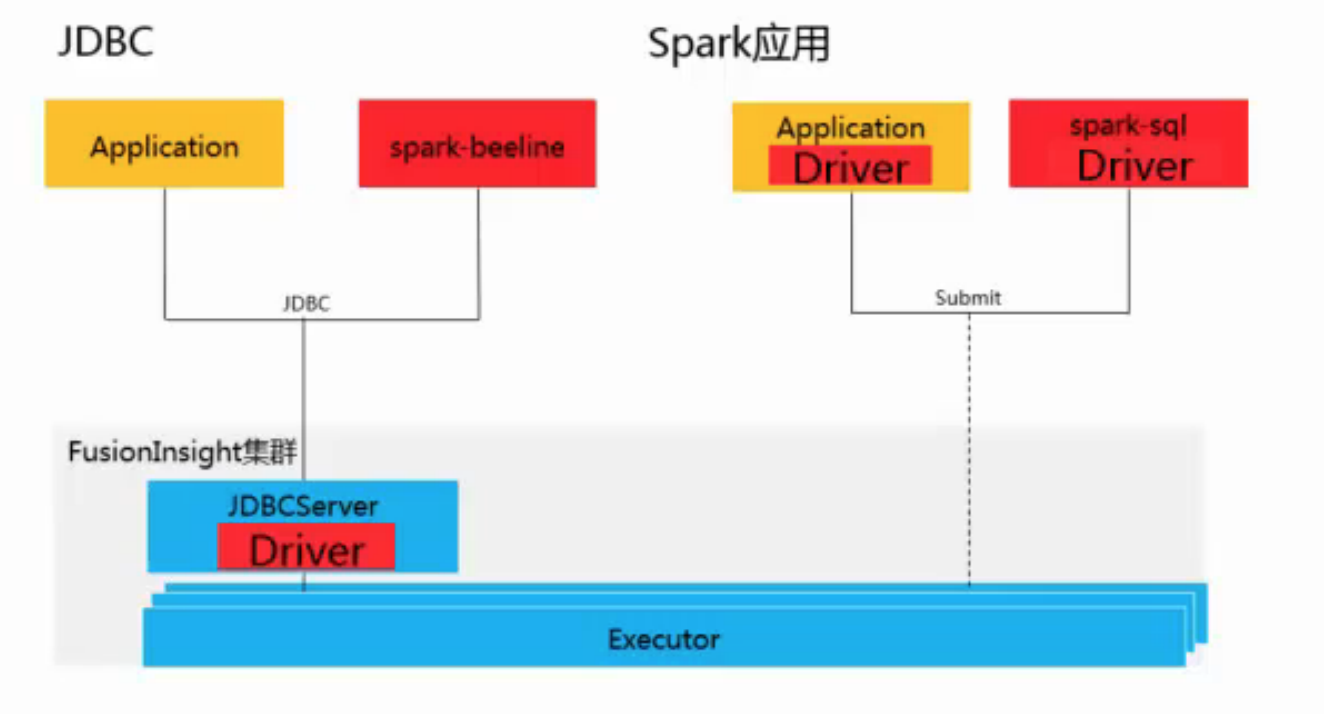
spark-beeline是作为客户端连接到JDBC server上,sql语句在jdbc应用中执行。
spark-sql是在客户端中直接启动spark应用,只支持spark-client模式。
DataFrame介绍:
以RDD为基础,带有Schema信息,类似传统数据库的二维表。注册成表之后可以使用类SQL操作
DataFrame是一个分布式的row信息的集合,其中数据被组织为命名的列
DataFrame常用Transformation算子:filter、groupBy、join、sort、select、intersect、dropDuplicates等
DataFrame常用action算子:collect、count、first、show、take等