Hadoop学习系列之:流式数据处理(二):storm计算框架
流式数据处理(二):storm计算框架
####1.Storm是什么
Storm是流式处理的计算框架。
- Storm是twitter开源的一个关于hadoop的实时数据处理框架
- Storm能实现高频数据和大规模数据的实时处理
特点:
- 事件驱动的类型,实时处理
- 实现连续查询
- 数据不存储,先计算
- 实时性强,低延迟
应用场景:
- 实时分析:实时日志处理、交通流量处理、股票信息处理等
- 实时统计:网站实时访问量、排序等
- 实时推荐:实时广告定位
术语:
- Topology:用于封装一个实时计算应用程序的逻辑,类似MR Job
- Stream消息流:是一个没有边界的tuple序列,tuples会被以一种分布式的方式并行创建和处理
- spouts:消息源,消息生产者,从一个外部源读取数据并向topology里面发出消息:tuple
- bolts:消息处理者,所有消息处理逻辑被封装在bolts里,处理输入的数据流并产生新的输出数据流,可执行过滤、聚合、查询数据库等操作
- task:每一个spout和bolt会被当做很多歌task在整个集群中执行,每一个task对应一个线程
- stream groupings:消息分发策略,定义一个topology的其中一步,定义每个tuple接受什么样的流作为输入;stream grouping用来定义一个stream应该如何分配给bolts们
2. Storm系统架构
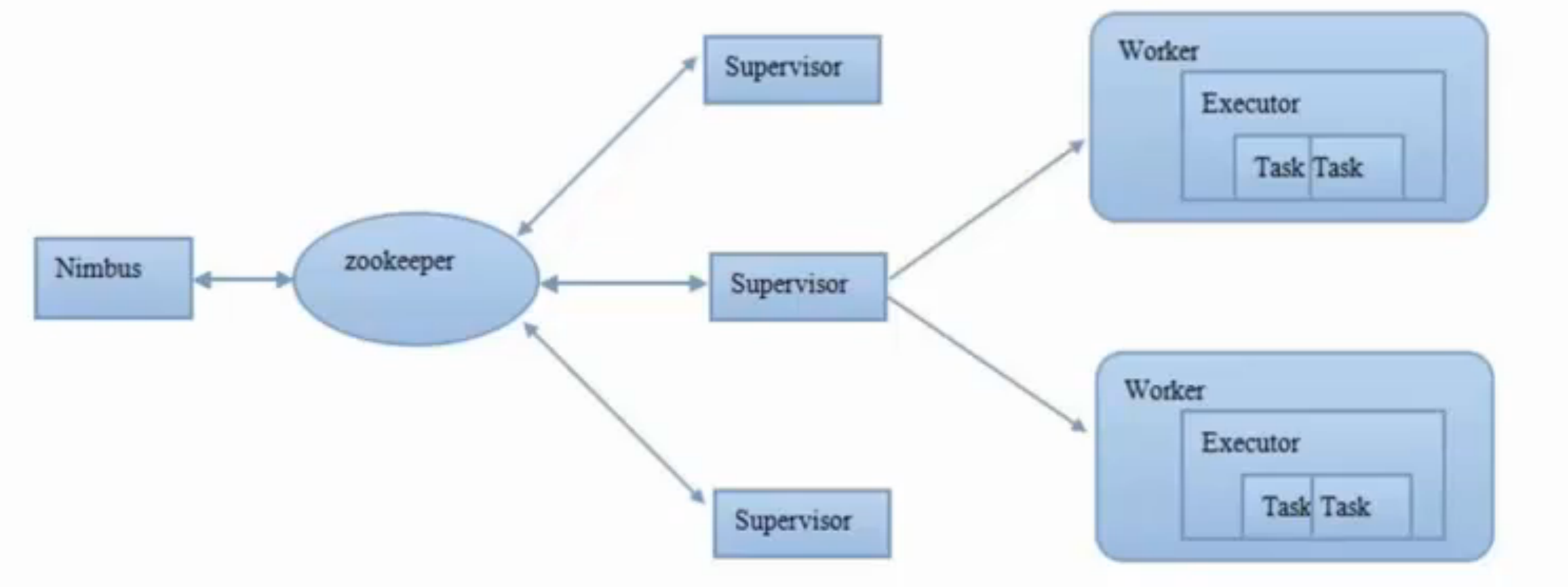
同样也是master/slaver主从结构,但是把master和slaver分开,靠zookeeper联系。
Nimbus:Storm大脑,强依赖zookeeper(所以是主备管理),负责分发代码、为worker分配任务、故障检测
zookeeper:元数据存储,在nimbus和supervisor中协调,把一个topology分成多个子topology
supervisor:负责监听自己所在机器上的工作
worker:
executor:执行一个topology子集
task:具体任务
####3. Storm性能特征
storm并行度
- storm集群中的1台物理机会启动1个或多个worker进程(jvm进程),每个worker进程运行某一个topology的executors,因此一个运行的topology是由多台机器上的多个worker进程组成的。
- 每个单独的work进程里会运行一个或多个executor线程,每个executor会运行同一个component(spout或bolt)的一个或多个task,线程数目可以动态调整(可以等于/小于task数目)
- 1个task是完成数据处理(代码)的实体单元(实例)
默认一个supervisor节点最多可以启动4个worker进程,每个topology默认占用一个worker进程,每个spout/bolt占用一个executor,每个executor默认启动一个task
Storm可靠性
- Worker进程死掉:storm会自动恢复(supervisor会尝试重启,数次不成功之后,supervisor会在这个服务器重新启动worker)
- supervision进程死掉:storm自动恢复,死亡状态下不会影响worker工作,原因同nimbus
- nimbus进程死掉(存在HA问题),启动快速失败或者无状态:意外情况下进程会自动毁灭,无状态意思就是所有状态会保存在zookeeper或本地磁盘中(zookeeper的解耦功能),死亡状态下不会影响worker工作,会重启。
- ack/fail消息确认机制:确保一个tuple被完全处理(完全处理的意思是:这个tuple以及由这个tuple所衍生的所有tuple都被成功处理)
- 每个streaming里面有一类特殊task—> ack,负责跟踪spout发出的每个tuple的tuple树。ack发现tuple树全部处理完成,会发送消息给产生tuple的task,成功返回ack,失败返回fail。
- 在spout发射tuple的时候会发送messageid,开启消息确认机制
- 如果topology里面tuple比较多,那么acker数量设置多一些,效率会提高
- 通过
config.setNumAckers(num)来设置一个topology里面acker的数量,默认值1。 - acker用了特殊的算法,使得对于追踪每个spout tuple的状态所需要的内存恒定(20bytes)
- 如果一个tuple在指定的
timeout(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS默认值30s)时间内没有被成功处理,那么这个tuple会认为处理失败了
####4. Storm的java编程:作业提交与停止方式
-
向集群提交作业
storm jar *.jar xxxxMainClass -
停止作业
- 先查询作业列表
storm list - 命令行下执行
storm kill TopologyName或在storm ui上点击kill按钮
- 先查询作业列表
storm和mapreduce区别就是,MR在运行结束后自动结束进程,但是storm需要手动kill