Hadoop学习系列之:流式数据处理(三):flume数据采集
流式数据处理(三):Flume数据采集
1. Flume定义
Flume是一个分布式、高可靠、高可用的服务,能够有效的收集、聚合、移动大量的日志数据。
适用场景:收集应用系统生成的日志信息,然后进行分析
不适用场景:大量数据的实时数据采集
主备管理
好处:
- 有一个简单、灵活的基于流的数据流结构
- 具有故障转移机制和负载均衡机制
- 使用了一个简单的可扩展数据模型(source,channel,sink),几乎不用用户自己开发client,对于每种数据源有相应的source去读取
- flume可以从规定目录下采集日志,然后归到目的地,提供实时采集日志信息到目的地的能力
- 也可以通过特定方式采集日志
- flume支持级联,提高并发性
flume-ng处理数据的两种方式:avro-client、agent:
- avro-client:一次性将数据传输到指定的avro服务器客户端
- agent:一个持续传输数据的服务
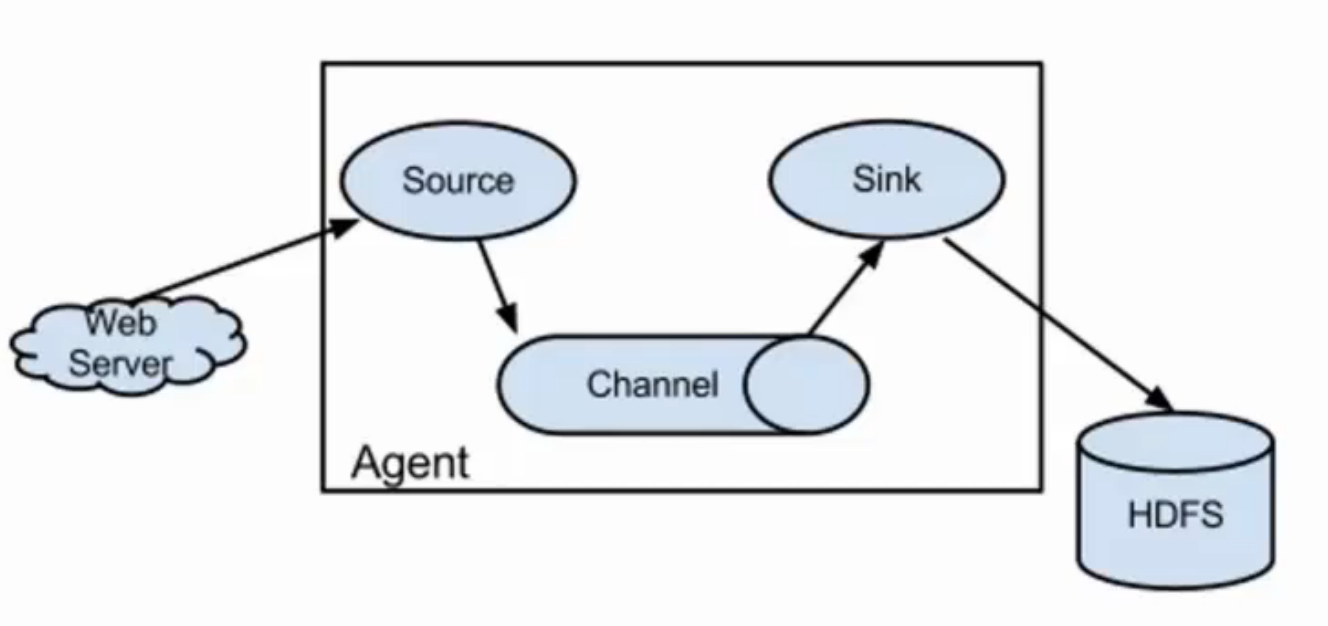
- Agent主要组件:Source、Channel、Sink
数据在组件传输的单位是Event,event就是flume中对数据的封装,也是flume中最小的模块
2. Flume系统架构
节点结构图
-
Source
主要作用:从外界采集各种类型数据,将数据传递给channel
Source种类:不需要用户自己去开发采集数据client了
- AvroSource:监听一个avro服务端口,采集avro数据序列化后的数据
- Thrift Source:监听一个thrift服务端口,采集thrift数据序列化后的数据
- Exec Source:基于unix的command在标注输出上采集数据
- JMS Source:java消息服务数据源,java消息服务是一个与具体平台无关的API,这是支持jms规范的数据源采集
- Spooling Directory Source:通过文件夹里的新增的文件作为数据源的采集
- Kafka Source:从kafka服务中采集数据
- NetCat Source:绑定的端口(tcp、udp),将流经端口的每一个文本行数据作为event输入
- HTTP Source:监听http post和get产生的数据的采集
-
Channel:一个数据的存储池,中间通道。有简单的清洗功能,也可以安装第三方插件对数据进行过滤清洗操作。
主要作用:接受source传出的数据,向sink指定的目的地传输。channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重写,不会造成数据丢失,因此很可靠。
channel类型:内存型(memory channel 使用内存作为数据存储,不对数据持久化,有可能造成数据丢失,但是内存计算速度快,吞吐量大)、jdbc数据源(JDBC channel 数据持久化,可靠高,基于嵌入式database的实现)、文件形式存储(file channel 基于war log实现的,也有持久化)等
常见采集的数据类型:memory channel、JDBC channel、Kafka channel、file channel、spillable memory channel(使用内存和文件作为数据的存储)等
-
Sink:数据最终的目的地
主要作用:接受channel写入的数据,以指定的形式表现出来(或存储或展示)
sink表现形式:打印到控制台、hdfs上、avro服务中、文件中等
常见采集的数据类型:HDFS sink、Hive sink、 Logger SINK、avro sink、thrift sink、file roll sink、hbase sink、kafka sink等
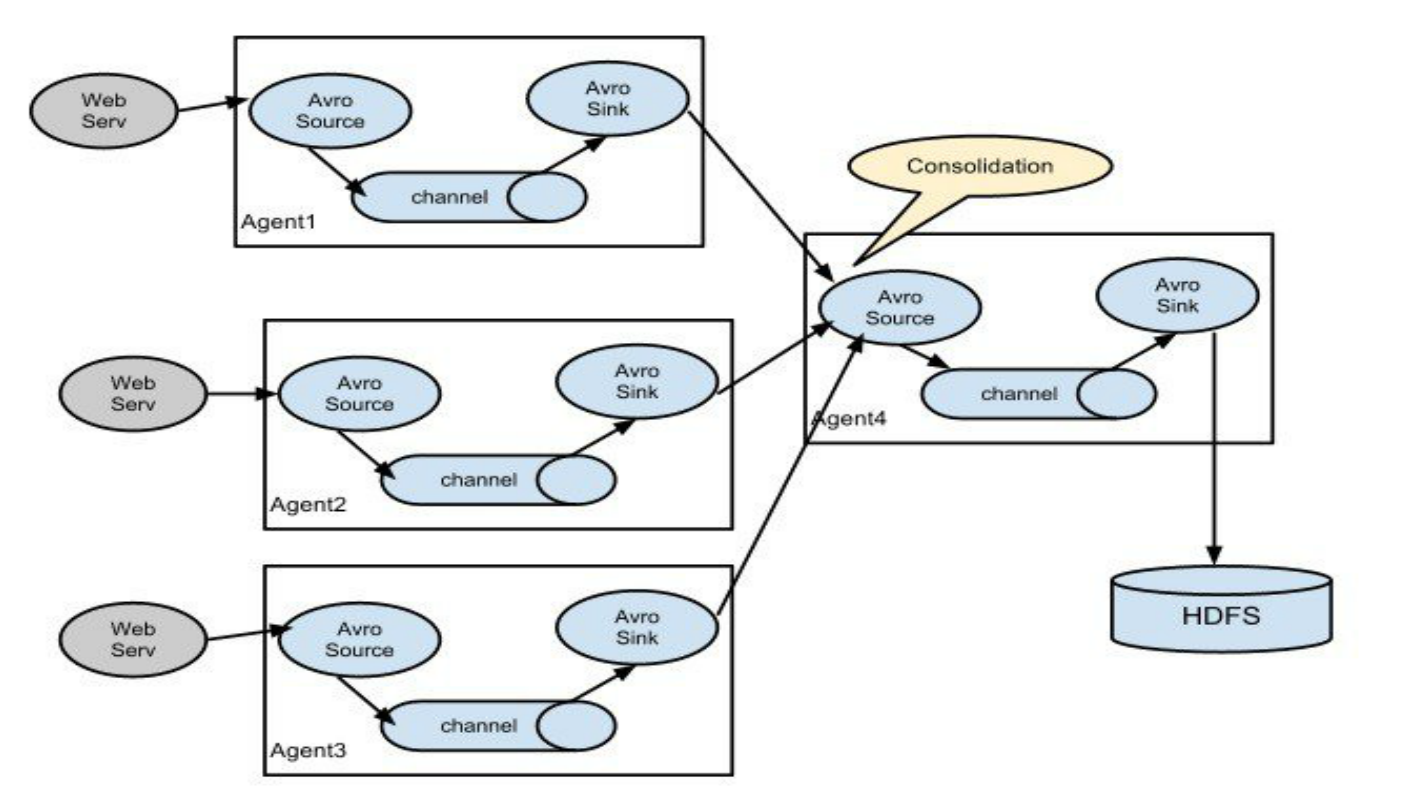
多agent架构(flume架构):
####3. Flume例子
-
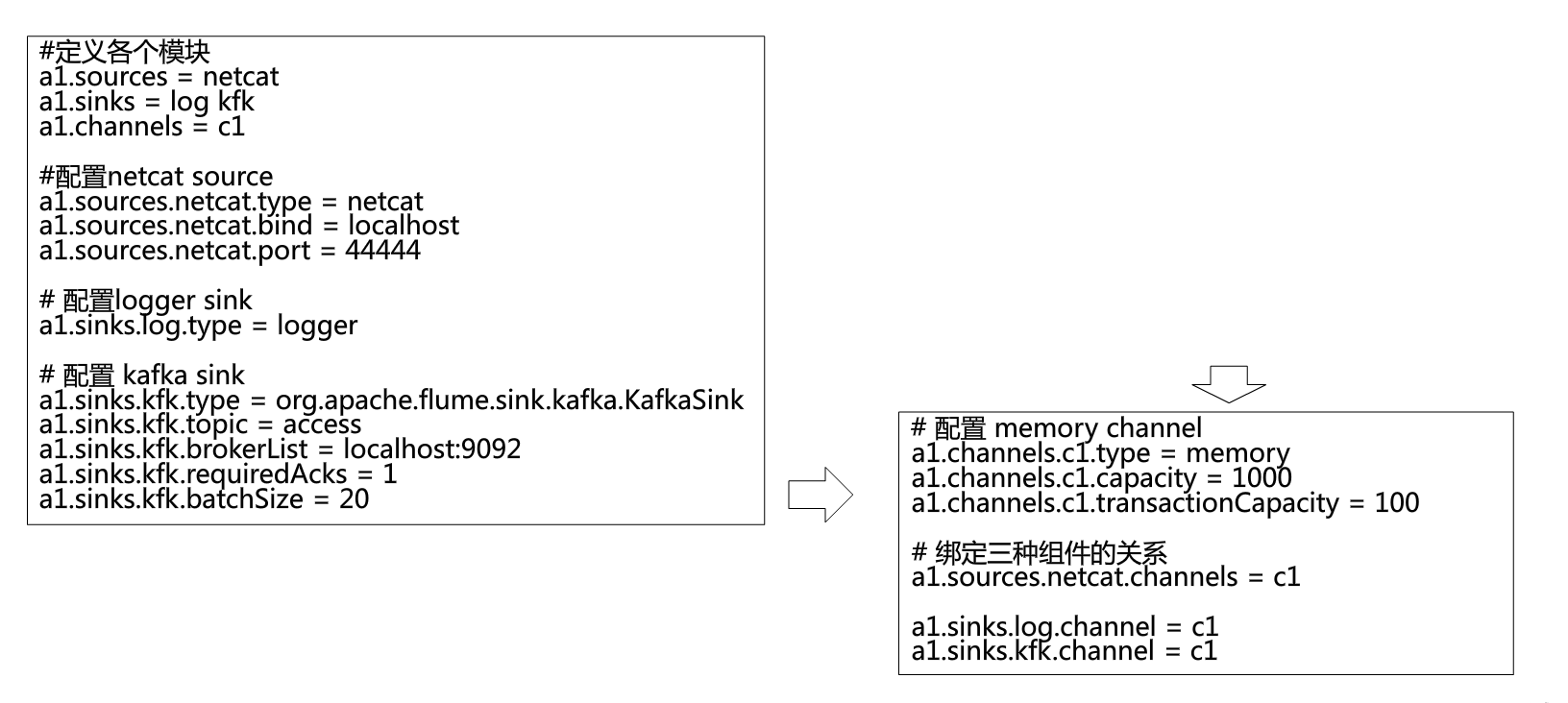
生成source并把数据通过channel 放到channel 中

-
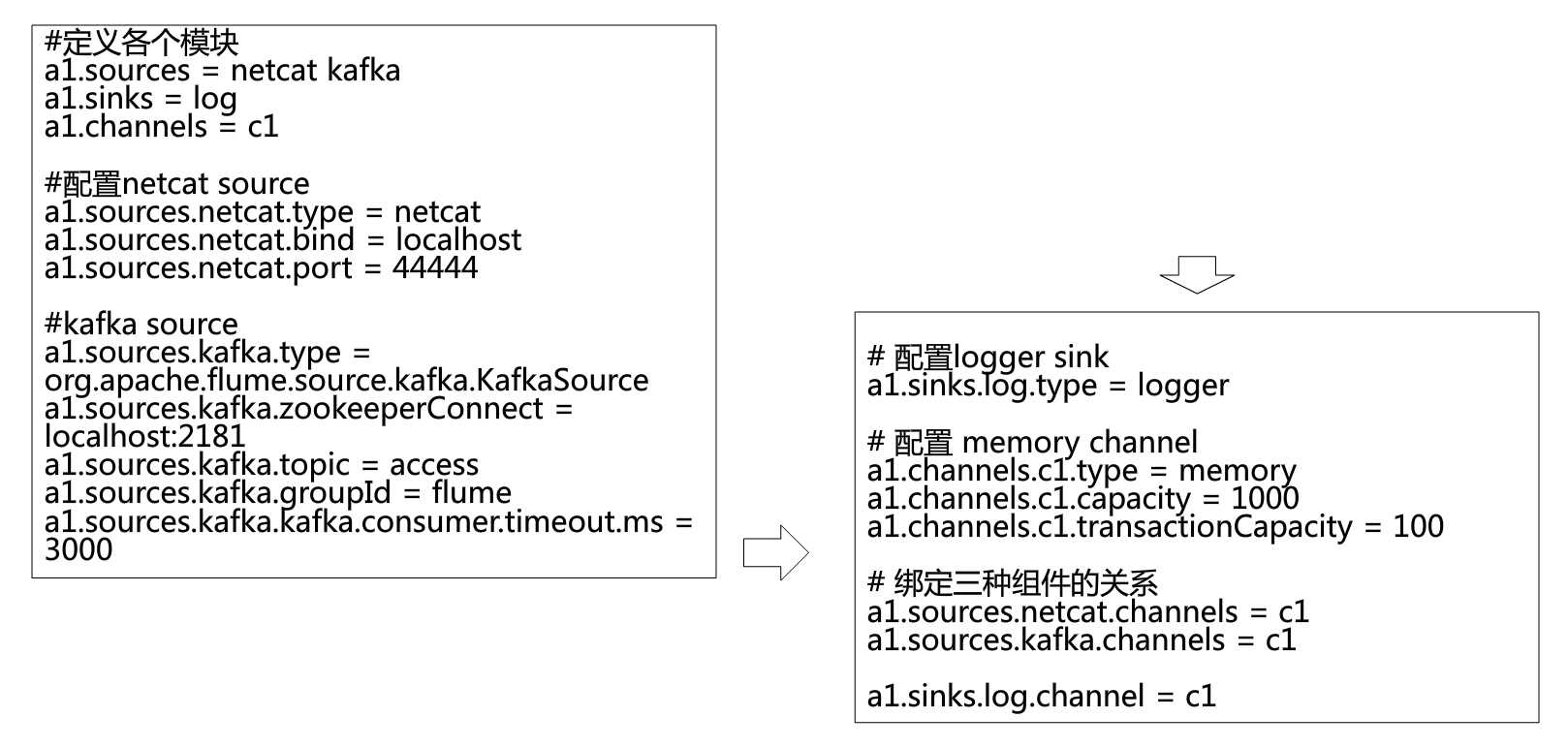
kafka作为数据源,从kafka中抓取数据并存到目的地
-
kafka sink