Hadoop学习系列之:流式数据处理(一):kafka消息队列
流式数据处理(一):Kafka消息队列
1. Kafka定义
高吞吐、分布式、基于发布订阅的消息系统。
Kafka特点:
- 高吞吐量
- 消息持久化到磁盘
- 分布式系统,易扩展
- 容错性好,不存在单点故障
- 多客户端支持
- 实时
- 利用kafka可以在廉价PC SERVER上搭建大规模消息订阅系统。
适用场景:大量数据的互联网服务的数据收集场景。
已对接组件:Streaing、Spark、Flume
Kafka优点:
- 解耦:消息产生(producer)和消费(consumer)系统可以独立变更
- 可靠:有效解决单点故障引发系统不可用问题
- 易扩展:生产、消费系统扩展简单
- 可恢复:消息缓存,支持故障后从故障点读取
- 异步通信:生产系统无需关心消费系统的消费时间
2. Kafka基本概念
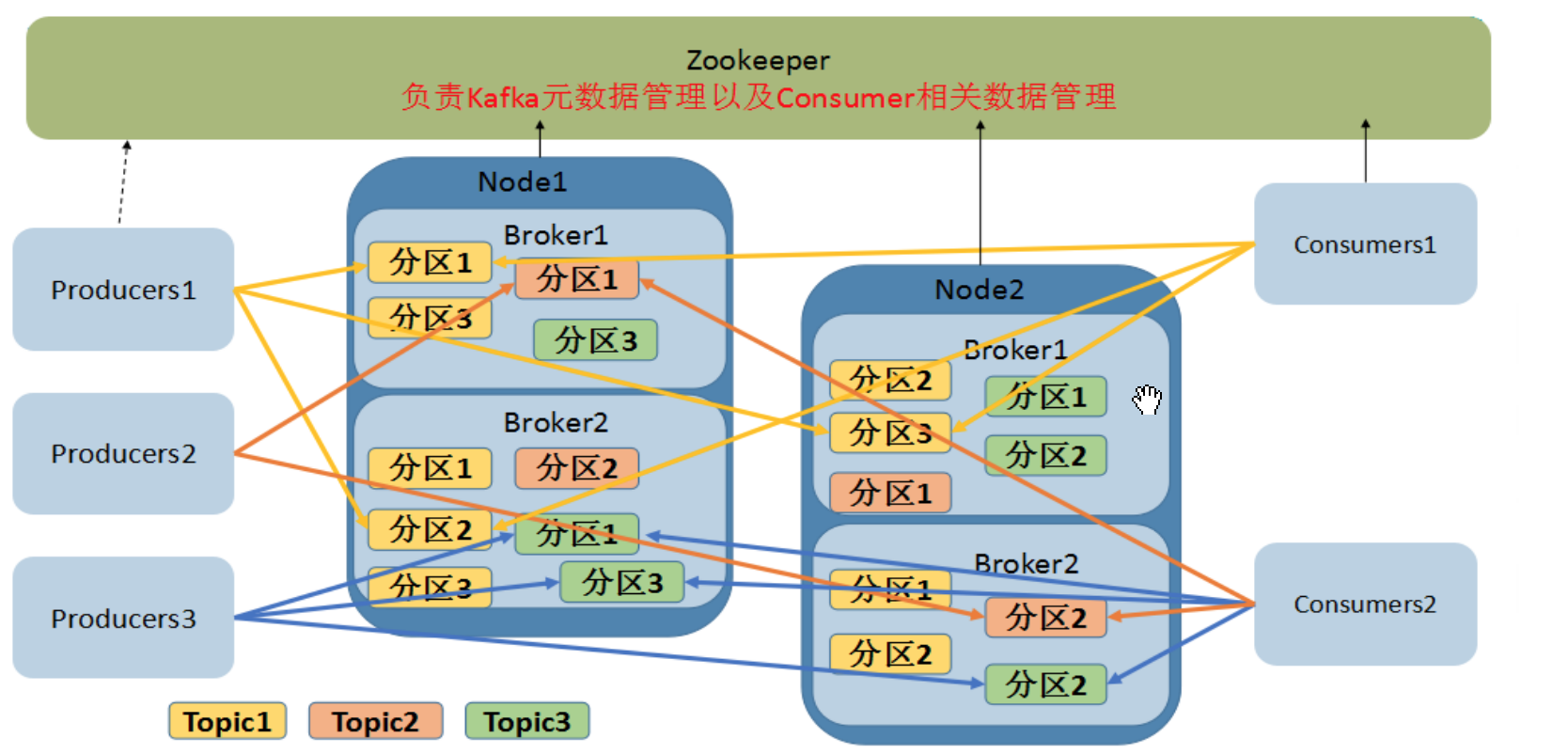
-
kafka部署的实例个数不得小于2
- zookeeper:负责kafka元数据管理、consumer相关数据管理
- Topic:kafka处理消息源的不同分类。创建topic时,副本数不得大于当前存活的broker实例个数,否则创建topic会失效。设置副本可以增强kafka服务的容灾能力。
- producer:决定将消息归属哪一个partition
- partition:topic物理上的分组,一个topic有多个partition,每个partition都是有序而不可变的队列。引入此机制保证kafka高吞吐量。partition中每条消息都分配一个有序ID,称之为offset,所以在生产和消费过程中,不需要关注数据存储的partition是在哪个broker上,只需要指定topic即可。是个.log文件。
- message:传递的数据对象。有四部分:offset,key,value,timestamp。offset,timestamp在集群中产生,key,value在producer产生
- broker:服务端,可以存储消息,不生产消息。kafka中一台或多台服务器成为broker,每个broker都是一个实例。为减少磁盘I/O调用的次数,broker会将消息暂时buffer起来,达到阈值时在flash到磁盘。有一个无状态机制,没有副本机制,进入无状态机制可能导致消息删除出现问题,因此引入基于时间的服务保证,一般7天再删除。不保存consumer状态。
- consumer:消息和数据的消费者,订阅topic和处理topic发布的消息。可以reverse back到任意位置进行重新消费,故障时可读取最小的offset进行重新消费记录。每个cosumer都属于一个consumer group。partition中的每个message只能被consumer group中的一个consumer(consumer 线程)消费,如果一个message可以被多个consumer消费,那这些consumer不能在一个组。但是一个consumer可以消费多个partition中的消息
- 对于一个topic,同一个group不能有多于这个topic的partition个数的consumer同时消费。
- kafka只能顺序读取消息。
- 每个partition都会被kafka实例保存。kafka支持partition恢复策略,可以通过配置文件配置partition副本个数,选出leader,负责kafka读写操作,其他的负责数据同步。kafka会把leader均衡到每个实例上,减少单点压力。
- 分区可以把分件内容分到不同broker中,避免文件过大。
3. Kafka架构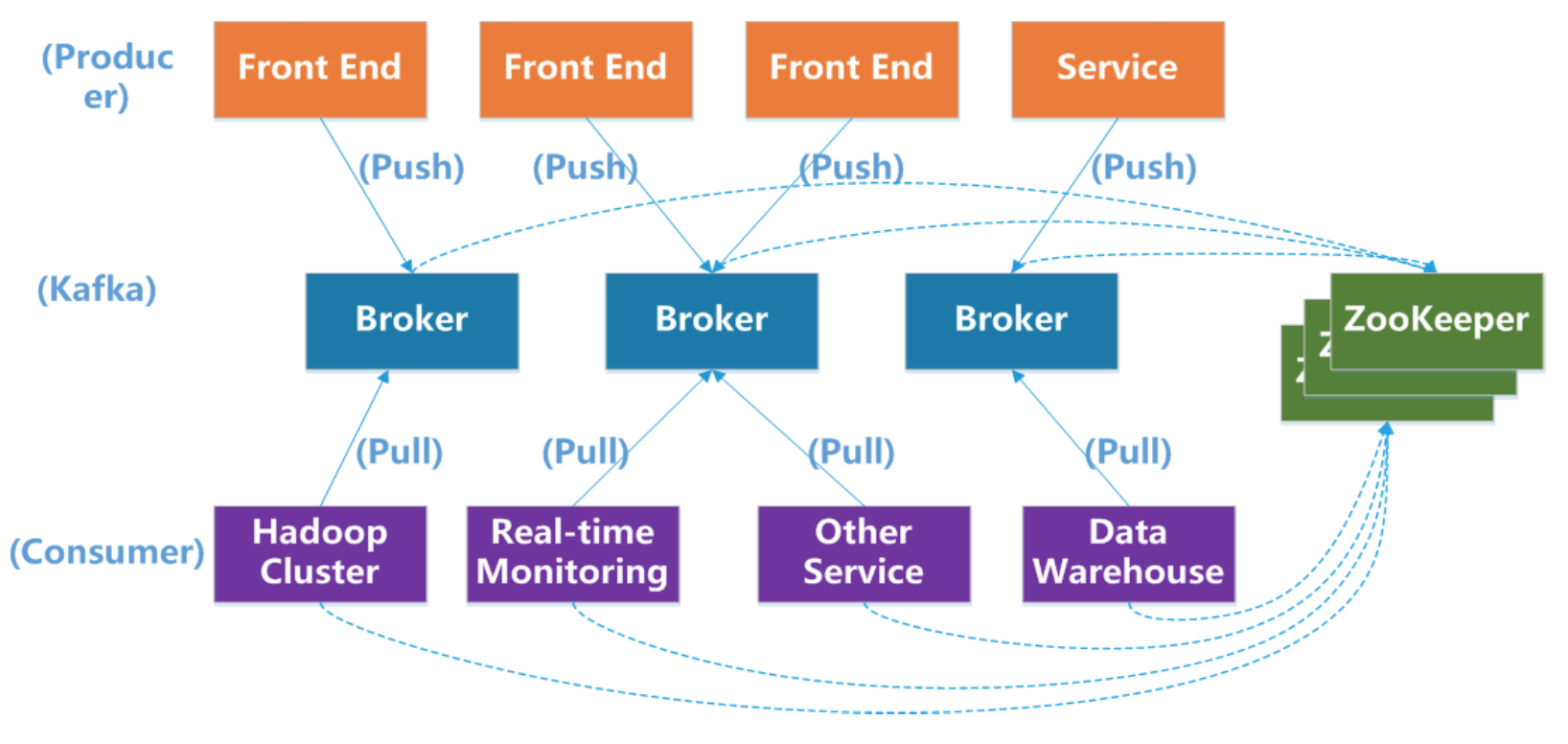
zookeeper在kafka中作用
- broker和consumer水平扩展。
- 存储元数据,管理consumer数据,当consumer数量发生变化, zookeeper需要对consumer进行再平衡。管理consumer和broker的动态加入和离开。consumer或broker加入或离开时触发负载均衡算法,由zookeeper指挥,使得一个consumer-broker类的多个consumer-borker订阅负载平衡
- 维护消费关系及每个partition的消费信息。
zookeeper如何实现作用:broker和consumerq启动后都会在zookeeper注册临时的broker/consumer registration。
4. kafka offset
每条消息在文件中的位置叫做offset,是一个long型数字,是唯一标记一条消息。kafka并没有提供其他额外的索引机制才存储offse,因为kafka中几乎不允许对消息进行随机读写。所以有新的消息,加在.log文件的尾部。
partition中每条message由offset来表示它在partition中的偏移量,但是offset不是该message在partition数据文件中的实际存储位置,而是逻辑上的一个值,唯一确定了partition中的一条message,可以认为是一个id。
5. kafka消息处理机制
- 发动到partition中的消息会按照它接受的顺序追加到日志中
- 对消费者,消费消息的顺序和日志中的消息顺序一致,就是先读取最老的信息
- 如果topic的“replication factor”为N,那么允许N-1个kafka实例失效
- kafka对消息的重复、丢失、错误以及顺序型没有严格要求
- kafka提供at-leat-once delivery,即当consumer宕机,有些消息会被重复delivery
- 因为每个partition只被consumer group中一个consumer消费,所以kafka保证每个partition内的消息会被顺序的订阅
- kafka为每条消息计算CRC校验用于错误检测,CRC校验不通过的消息会被直接丢弃
- ack校验,当消费者消费成功,返回ack信息
6. kafka客户端操作
-
创建topic:创建一个“test”的topic,一个分区一个副本
bin/kafka-topics.sh --create --zookeeper localhost:24002/kafka --replication-factor 3 --partitions 3 --topic test -
查看主题
bin/kafka-topics.sh --list --zookeeper localhost:24002/kafka test -
创建生产者
bin/kafka-console-producer.sh --broker-list localhost:21005 --topic test -
创建消费者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning或者
bin/kafka-console-consumer.sh --topic test --bootstrap-server localhost:21005 --new-consumer --consumer.config config/consumer.properties
开源的zookeeper端口号是2181。
退出是
control+c
kafka安装及运行日志保存路径为/vr/
删除topic时,必须确保kafka的服务配置
delete.topic.enable配置为对必须使用
admin用户或者kafkaadmin组用户创建topic
未读资料:https://blog.csdn.net/ychenfeng/article/details/74980531