Hadoop学习系列之:hbase
Hbase学习笔记
Hbase概述
HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的可分布式存储系统,利用Hbase可以再廉价PC SERVER上搭建大规模模块化存储集群。
- 是分布式开源数据库,对表的处理结果还是要存在HDFS中,所以是基于Hadoop分布式文件系统
- 处理非常庞大的表(表的元素是上亿级别)
- 对大表数据的读写访问可以达到实时
- 利用mapreduce计算数据,利用zookeeper协调资源
- 可以同时处理结构化、 非结构化数据和半结构化数据
- 不需要数据有传统的ACID(原则性、一致性、独立性、持久性)特性
列式数据库vs行式数据库
- 所有数据按列存储
- 行式数据库在做一些列分析,必须把所有列的信息全部读取出来;而列式数据库由于按照列存取,因此只需要对特定列进行I/O操作,效率节省90%
- 列式数据库在每列上有专门的列压缩算法,提高数据库性能,行式数据库不具备
- 行式存储,如果某一列是空值,就要存入空的字符串,占据空间,导致资源浪费;列式存储,如果某一列为空,可以不存,节约空间。
Hbase系统架构
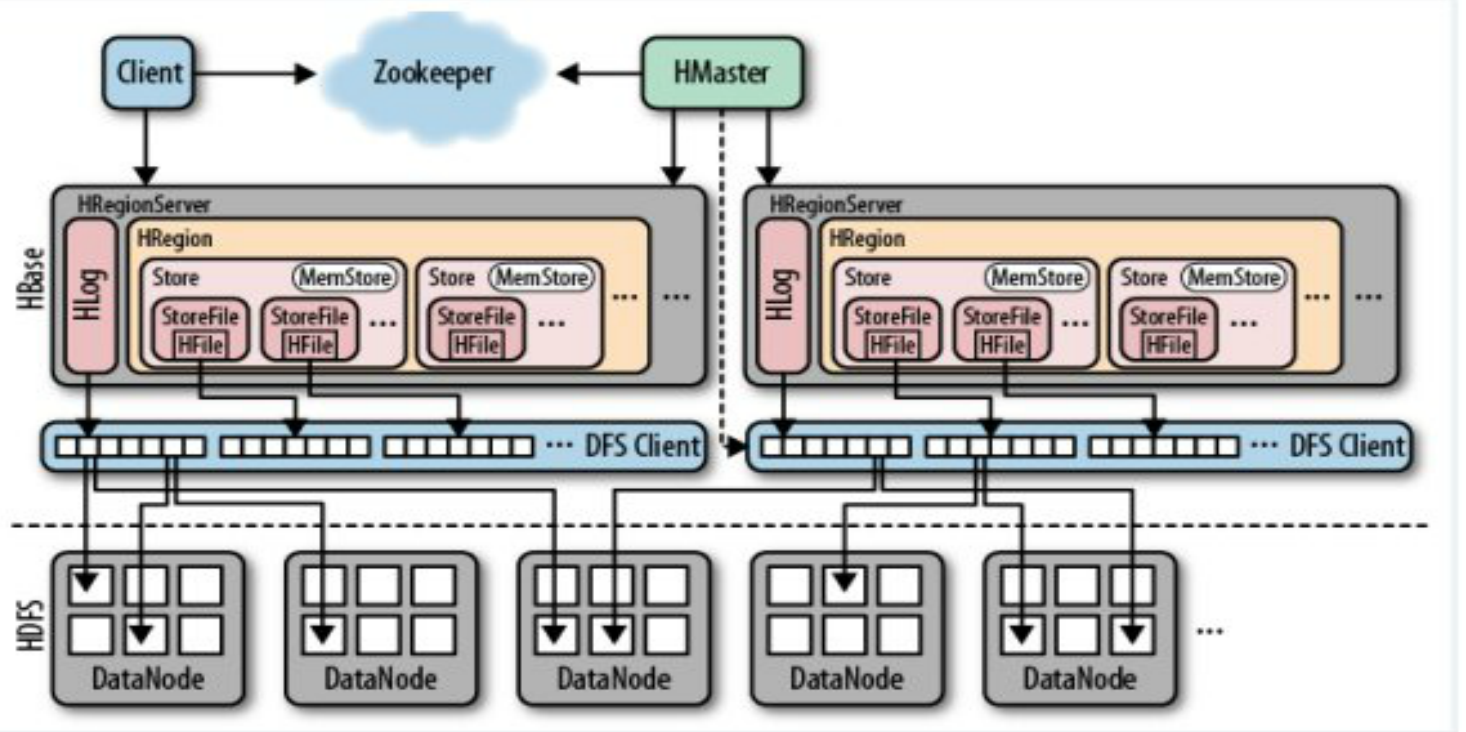
master/slaver架构
- Client:提出请求
- zookeeper:有微型数据库功能
- HMaster:Hbase的老大(类似yarn的RM),存在主备HMaster,受ZOOKEEPER调控,管理多个Hregionserver
- HRegionServer:类似yarn里面的NM,内含多个HRegion
- HLog:对每次往memorystore写的数据进行备份,预防服务器宕机内存数据丢失问题;并行多个HRegion
- HRegion:内含多个Store
- Store
- StoreFile:这是一个逻辑概念,物理文件为.hf文件。
- MemoryStore:通过内存进行写操作,计算速度快,所以可以达到实时效果。但是有数据安全性问题。内存写满、HLog磁盘空间写满或WAL达到阈值之后触发FLUSH操作,把数据刷到磁盘,生成HFile(.hf)文件。
- Store
- HDFS:每一个store生成的.hf文件药存在HDFS里面。.hf通过MR方式刷到hdfs的datanode中。HMaster监控DFS Client,就是监控MR过程,保证三副本。
Hbase读流程
Hbase写流程
Hbase数据模型
在HBase中,数据存储在具有行和列的表中,Hbase的表是稀疏、多位映射的。HBase用键值对的方式存储数据,每个值都是未经解释的字符串,通过行键、列值、列限定符、时间戳进行定位。
HBase数据模型基本概念:
- 表:由行和列组成
- 行:由Row key和若干列组成。行是通过row key按照字典方式排列的,读取按照row key扫描
- 列族:column family,一个列族可以由任意多个列组成,需要在建表之处设置好;是region的物理存储单元,同一个region下的多个列族存在不同的store下;列族信息是表级别的配置,同一个表多个region都有相同的列族信息;不是每一行的列族都存储了信息,因为hbase的表具有稀疏性。
- 列限定符:column qualifier。列族中添加不同列限定符可以对信息进行划分定位;以列族名作为前缀,以“:”连接后缀;是列族的一个标签,可以动态扩展,无需提前规定
- 单元格:cell,一个单元格保存一个值多个版本,通过行键、列族和列限定符进行定位,每个版本对应一个时间戳
- 时间戳:TimeStamp,区别同一条数据的不同版本
- 命名空间:NameSpace,表的逻辑分组
底层数据以key-value形式存在,具有特定格式。
Region代表一个个子表,按照Row key进行划分,把大表划分成子表,Region只需要记住start row key就可以了。
Region是HBase分布式存储的最基本单元,最基本的物理单元是column family。
Region分为user region(存储具体信息)和meta region(存储路由地址信息)。meta region的路由地址信息存储在zookeeper中。用户region路由地址信息存在mata表之中(这就是zookeeper充当微型数据库功能)。
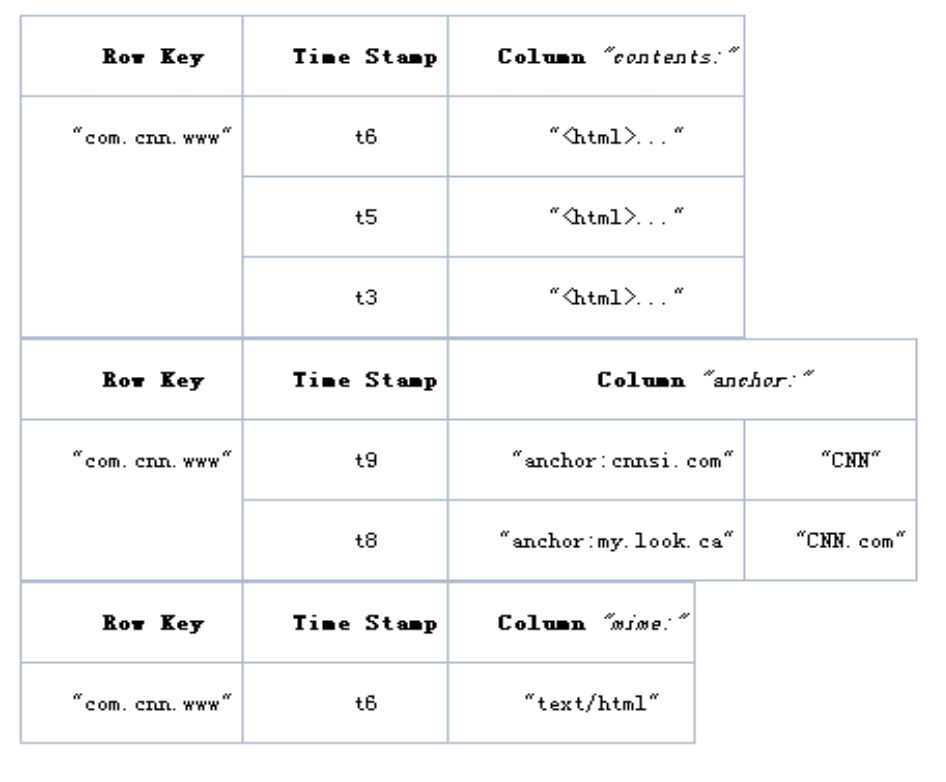
数据模型-逻辑模型
key-value:
实际上列式的存储的
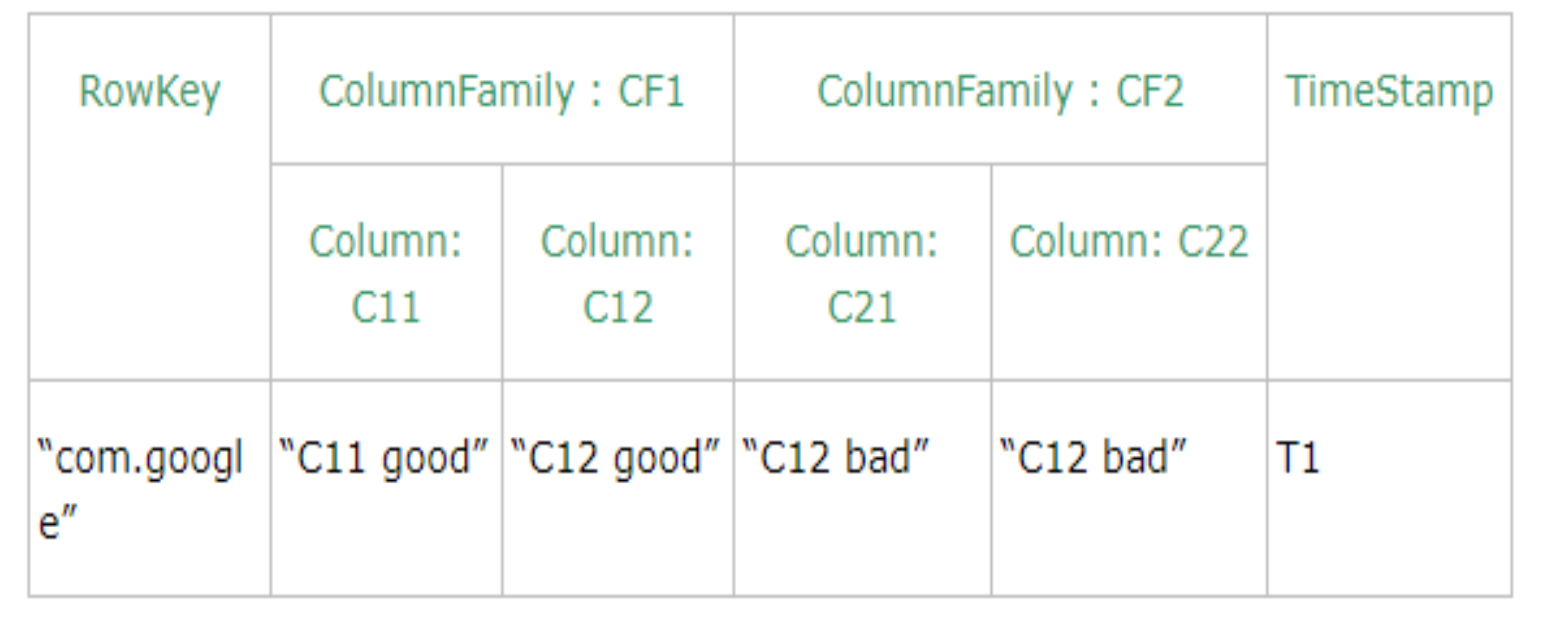
数据模型-物理模型
将逻辑模型的一个row分割成根据column family存储的物理模型。
一个列族可以有多个HFile,但是一个HFile不能存储多个列族 ,每个列族都有一个memory store,一行中的列族数据需要物理的存放在一起,不一定存放在一个hfile。
key-value:4坐标=key,单元数据=value。单元数据维度越少,对应值的范围越光。
HBase的Compaction过程
当HFile数据越来越多,针对同样的查询需要同时打开的文件越来,查询延时越来越长,此时HBase会启动Compaction操作,目的是减少同一个Region、同一个列族下面的小文件数目,从而提升读取的性能。
- Minor Compaction:一般是3-10个HFile文件合并成大的文件
- Major Compaction:把涉及该region该列族下面的所有HFile文件。
HBase删除操作:进行Major Compaction时查看key-vlaue,如果标识符有delete,此时会执行删除操作。shell操作中delete就是添加删除标识符。
HBase分割操作:进行Major Compaction时查看key-vlaue,如果标识符有splite,此时会执行分割操作。
HBase的java API
HBase的表设计原则
HBase自身特点:
- row key 决定行操作任务进入regionserver数量,尽量让一次操作调用更多的regionserver,达到分布式目的
- row key决定查询读取连续磁盘块数量,最理想的是一次读取一个磁盘块
- column family决定查询读取的文件数,尽量减少column family数目
- row key数量由查询条件确定,column family由查询结果确定
Hbase的shell操作以及优化
####Hbase表设计
设计内容通过不同维度分为:表设计,column family设计,column qualifier设计
- 表设计:建表的方法,对region进行预分;识别可能的热点row key区域;考虑表属性、系统并发能力,利用分布式能力提高业务吞吐量;利用过期时间、版本设计等操作让表能自动清理过期数据。将row key设计的连续,适当分散提高并发度。在连续读的时候使用scan接口。
- row key设计:
- 属性值内容:常用的查询场景数据,选取什么内容作为row key
- 属性值顺序:离散度好、访问权重高的属性值放前面
- 时间属性:循环Key+TTL;周期建表
- 多业务场景共用row key导致数据访问矛盾问题:折中法、冗余法、二级索引
- row key设计:
- column family设计
- 可枚举数量少、扩展性弱的属性作为family
- 不同family设置不同属性
- 考虑因素:如何分表和如何分family;同时读取的数据放在同一个family;均衡family的数量
- qualifier设计
- 不可枚举、数量多且扩展性强的属性
- 原则:同时访问的数据存在同一个cell;列名尽量简短
Hbase性能调优
- 表的设计:预先创建一些空regions,当数据写入HBase中会按照region分区情况,在集群做数据的负载均衡。如果默认的话开始只自动创建一个region
- rowkey设计:设计rowkey时充分利用字典排序这个特点
- 列族的设计:不要在一张表中定义太多的column family,目前hbase只能处理2-3个的
- 缓存控制:创建表时,可以通过HColumnDescriptor.setInMemory(true)将表放在RegionServer的缓存中
- 版本控制:创建表时,可以通过HColumnDescriptor.setMaxVersion(int maxVersions)设置表中数据的最大版本
- 生命周期:创建表时,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据存储生命期,国企数据自动删除
- 合并和分割:当一个Store中的StoreFile达到一定阙值,进行major compaction;当其大小到一定阈值,又会进行分割split,等分成两个。通过合并过程比split过程快。split开始是仅仅把元数据存到一个新的region中时,但是实际信息转移发生在compaction过程。