Hadoop学习系列之:hive数据仓库
Hive学习笔记
Hive是什么
HIVE是基于Hadoop的数据仓库软件,可以查询和管理PB级的分布式数据。Hive和HDFS的关系类似于MySQL和磁盘的关系。
HIVE特点
- 支持ETL(Extract-Transform-load)操作
- 提供多种文件格式元数据服务
- 可以直接访问hdfs和hbase文件
- hive支持MR和spark等计算引擎
HIVE优点
- HA高可靠性,集群部署模式,元数据(hive元数据包括表名、表的列、表的分区、表的属性、表目录)存储在Metastore里面。Metastore是关系型数据库
- 使用类sql语言(即hql),是sql解析引擎,将sql语句转成MR job然后进行操作
- 扩展性好,自带函数多并且支持自定义编译函数(UDF)
- 支持很多接口
HIVE缺点
- 处理数据延迟度高(因为MR),查询速度慢
- hive不支持物化视图,不能再视图上更新、删除、插入数据
- 不适用于OLTP(联机事物处理:日常事物处理,要求/适合实时性、小数据量、交易确定、高并发性),适用于OLAP(联机分析处理:适合复杂动态报表,不要求实时性,数据量很大)
- 暂时不支持数据存储,只能用utf实现一些逻辑的处理,HIVE只是对数据进行操作后存储到HDFS中
- 不支持交互查询
hive数据存储
- 存储基于Hadoop HDFS
- 没有专门的数据存储格式(体现hive多元化,特殊性)。hdfs最小存储模块是block(128M),yarn里面的container,spark的idd文件等等都是有数据封装格式的。
- 存储结构主要包括:数据库,文件,表,视图,索引
- hive默认可以直接加载文本文件(textfile),还支持sequenFile、RCFile
- 在创建表的时候, 可以指定HIVE数据的列分隔符与行分隔符,HIVE即可解析数据
HIVE的系统架构
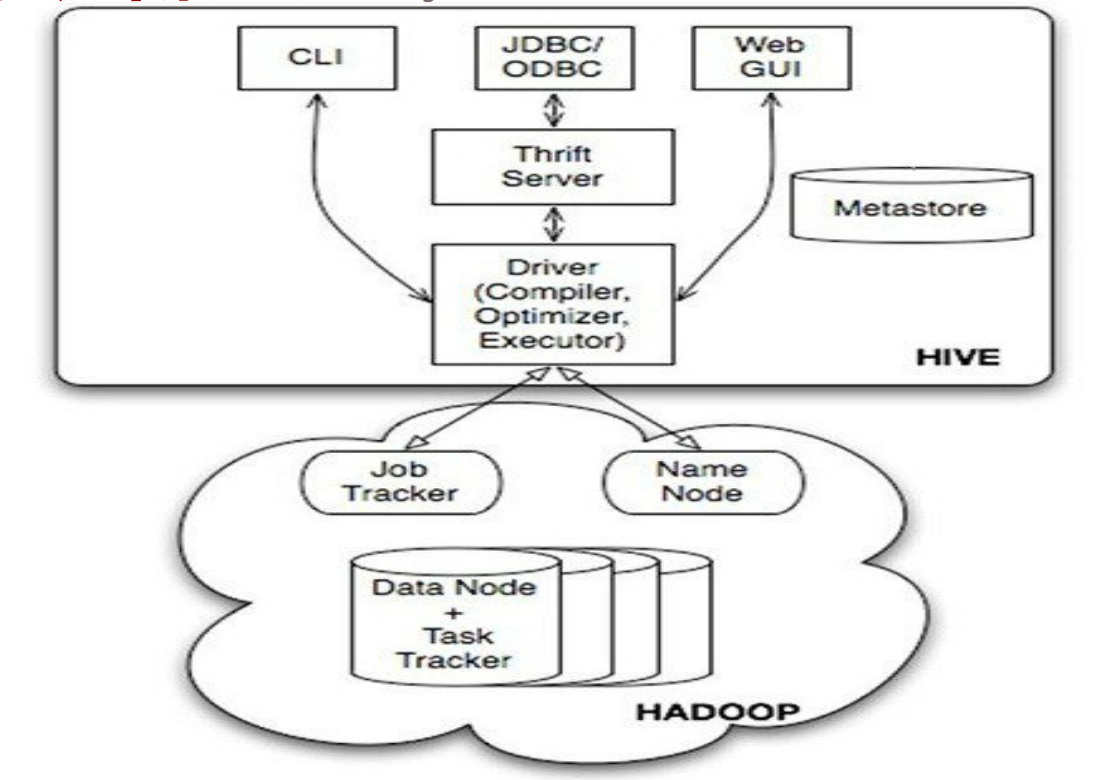
- Driver:hive大脑,管理Hive执行的生命周期,贯穿Hive任务整个执行期间
- Compiler:编译HiveQL并将其转化成一系列相互依赖的MapReduce任务
- Optimizer:
- Executor:
- metastore:存储hive元数据,是关系型数据库
- ThriftServer:提供thrift接口,作为JDBC和ODBC服务端,并将Hive和其他应用程序集成起来
- DBServer:接口
HIVE数据类型和表操作
HIVE数据类型
- 基础数据类型:TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINATY,TIMESTAMP,DECIMAL,CHAR,VARCHAR,DATE
- 复杂数据类型:ARRAY,MAP,STRUCT,UNION
HIVE数据存储模型
颗粒度从低到高:
- 数据库
- 表:理解为HDFS的目录
- 分区:理解为HDFS目录下的文件夹,数量不定
- 桶:理解为具体文件,数据可以桶的方式不同把不同数据放在不同的表里面,建表时可以定义桶的个数,桶可以进行排序,采取方式是对列值的哈希,方便进行数据抽样、优化等,获得更高的查询效率。
- 倾斜数据:数据集中到个别数据值的场景
- 正常数据
HIVE数据存储模型-托管表和外部表
HIVE默认托管表,又称为内部表,由HIVE管理数据,意味着HIVE会把数据一定到数据仓库目录。
外部表:HIVE可以去仓库目录以外的位置访问数据。
| 托管表 | 外部表 | |
|---|---|---|
| CREATE/LOAD | 把数据移到仓库目录 | 创建表时指明外部数据位置 |
| DROP | 同时删除元数据和数据 | 只删除元数据 |
如果只是用HIVE进行数据操作的就使用托管表
如果需要与外部工具一起进行数据操作,就使用外部表。
HIVE的UDF操作
HIVE的操作语句一定以
;结尾
-
UDF函数可以直接用于select语句,对查询结构做格式化处理后再输出内容
-
编写UDF函数需要注意:
- 自定义UDF需要继承org.apache.hadoop.hive.ql.UDF
- 需要实现evaluate函数,此函数支持重载
-
步骤
-
把程序打包放到目标机器
-
进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
-
创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS ‘hive.udf.Add’
-
查询SQL语句:
SELECT add_example(8,9) FROM scores;
-
销毁临时函数:hive>DROP TEMPORARY FUNCTION add_example;
-
-
UDF只能实现一进一出操作,如果需要实现多进一出,需要实现UDAF
出现了类似”cannot modify xxx at Runtime”错误时原因可能是“白名单里无此参数”
通过OM页面进行Hive日志收集,可以指定节点IP、特定用户、时间段进行日志收集,但是不可以指定实例进行日志收集。