Hadoop学习系列之:hdfs技术原理
HDFS技术原理
####1. HDFS概述
首先介绍一下文件系统File System包括:
- 索引:元数据(metadata)
- 包括文件名、文件长度、用户组、存储位置(路由信息),一般大小为150k
- 数据块block
HDFS:Hadoop Distributed File System分布式文件系统
HDFS适合大文件存储、流式数据访问,不适合大量小文件(因为文件metadata也占用存储空间)、随机写入、低延迟读取。
HDFS优点:
- 高容错性:服务器宕机,剩下服务器能保护系统正常运行
- 高吞吐量:大量数据访问的应用提供高吞吐量支持
- 大文件存储:支持TB-PB级别的数据
HDFS特点:一次写入,多次更改
####2. HDFS系统架构
HDFS是master/slaver主从结构——NameNode/DataNode
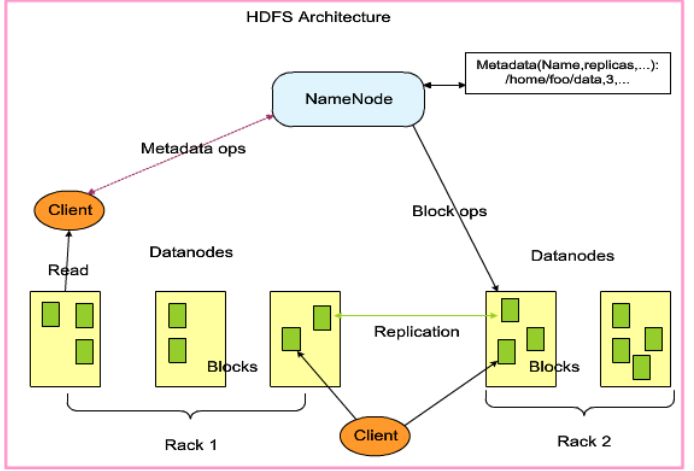
- NameNode负责存储元数据,为HDFS的大脑;NN不存在单点问题,因为其具有HA高可靠性,依赖zookeeper进行主备管理
- DataNode
HDFS作为存储系统,主要进行的操作为读取和写入操作
2.1 HDFS写入流程
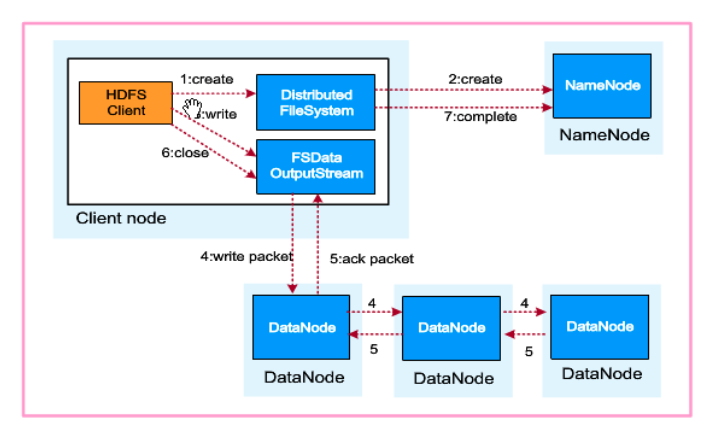
- 第3步是client执行write API操作
- 3个DataNode代表三副本存储策略,是HDFS的一个关键特性,在下文介绍
- 注意第6步close操作
- 第7步complete:namenode中进行元数据持久化到磁盘上
2.2 HDFS读取流程
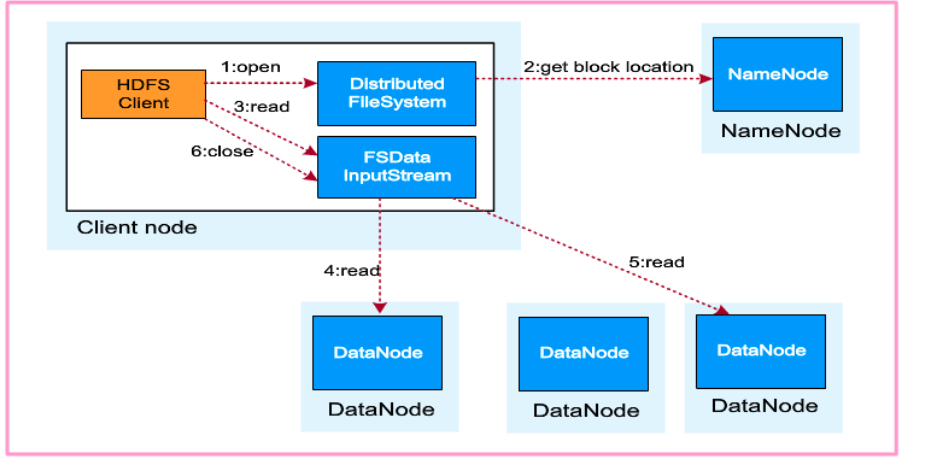
- 注意第6步close操作
- hdfs写入时会写三份,但是读取时只读一份,且读取与client逻辑上距离最近的blocks上的那一份
3. HDFS关键特性
HDFS关键特性包括:联邦存储机制、数据存储策略、HA高可靠性、多方式访问机制、空间回收机制、NameNode/DataNode主从模式、统一的文件系统命名空间、数据副本机制、元数据持久化机制、健壮机制。
3.1 数据副本机制
-
Distance(逻辑上的)计算方法:以下图为例
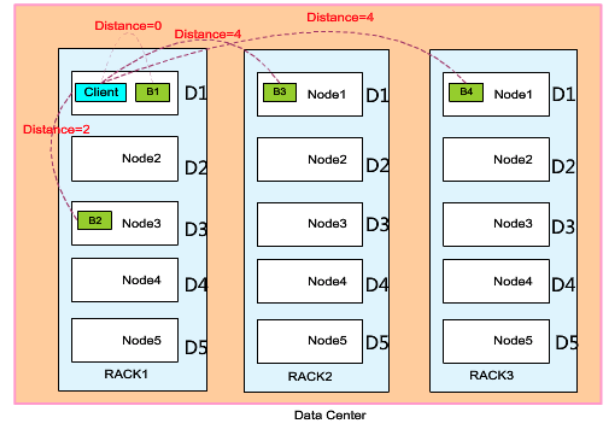
- 相同机架(rack)上相同服务器(node):D=0
- 相同rack不同服务器:D=node间距离
- 不同rack上:D=4
-
3副本选择:数据在写入时保存三分
- 第一份:data存入与client相同node上
- 第二份:副本存入与client相同rack不同node上
- 第三份:副本存入不同rack上
如果某node宕机,namenode会发现,并且立刻在其他地方copy一份,保证三副本
3.2 hdfs系统高可靠性
HA高可靠性,High Available,是双机集群系统简称,指高可用性集群,一般有2个或以上节点,分为活动(active)与备用(standby)节点
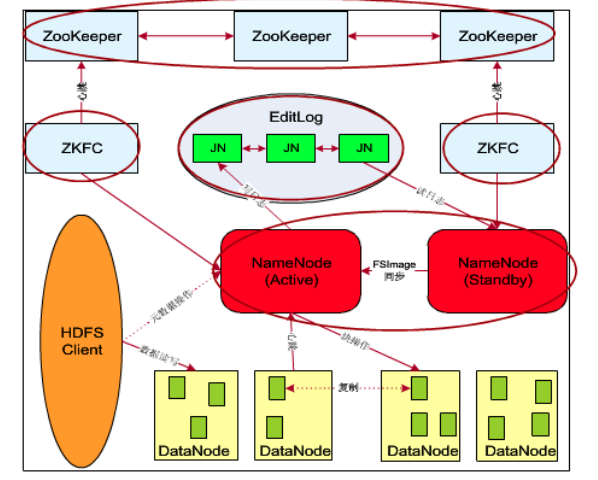
在基础架构之上增加以下组件:
- zookeeper:管理主备NameNode,通过ZKFC反馈NN状态,ZKFC数量与NN数量一致
- Journal Node:日志机制,操作元数据,同时元数据保存在NameNode上,DataNode读取数据时会校验
- NameNode active和standby,主备NodeNode,详细见下文
3.3 元数据持久化
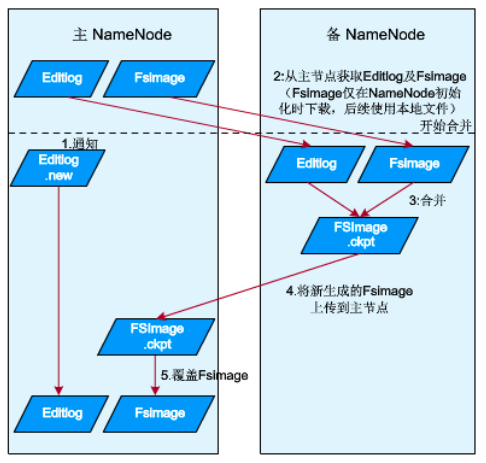
元数据持久化就是主备NN之间数据的流转(同步)。
-
主NN节点有EditLog和Fsimage文件,Fsimage文件是阶段性保存的文件镜像
-
备NN通知主NN生成新的日志文件(Editlog.new),以后的日志写到新的日志文件中
-
备NN从主NN获得Fsimage以及位于JournalNode上的旧的EditLog
-
触发合并,生成新的元数据文件FSImage.ckpt
按照实际(1h)或者editlog存满64M触发合并,这是就是进行一次元数据持久化
-
备NN将新生成的元数据上传到主NN,覆盖主NN的原有Fsimage文件。
-
循环步骤
由以上步骤可以看出,NN磁盘元数据文件是由备NN生成,进程元数据持久化过程。
3.4 元数据持久化健壮机制
- 重建失效数据盘的副本数据:DN向NN周期上报失败时,NN发起副本重建动作恢复丢失副本
- 集群数据均衡:HDFS架构设计了数据均衡机制,保证数据在各个DN上分布平均
- 数据有效性保证:DN数据在读取时校验失败,则从其他节点读取数据
- 元数据可靠性保证:采用日志机制操作元数据,同时元数据存放在主备NN上;快照机制实现文件系统常见的快照,保证数据误操作时能及时恢复
- 安全模式:HDFS提供独有安全模式机制,在数据节点故障、硬盘故障时能防止故障扩散
3.5 其他要点说明
- 统一文件系统:HDFS对外呈现一个统一的文件系统
- 统一的通讯协议:统一采用RPC方式通信。NN被动接收client和DN的RPC请求
- 空间回收机制:支持回收站机制,以及副本数的动态设置机制
- 数据组织:数据存储以数据块为单位,存储在操作系统的hdfs文件系统上
- 访问方式:提供JAVA API, HTTP方式,SHELL方式访问HDFS数据